
Distributed Wordpress with Kubernetes and CoreOS
In a previous post I unearthed how I put together a distributed wordpress cluster running in a multi-node CoreOS cluster.
In this post I’ll explore what it takes to get the same topology running on Kubernetes and CoreOS with help from VirtualBox and Vagrant. Vagrant provides a way to emulate the setup of a Production environment, locally - which is very handy. I started setting up my own cluster in the cloud, but I got stuck with the maze of TLS steps, so I’ll make a todo to figure that out and blog about that another time. I found the Kubernetes guides to be a bit spaghetti at this time.
Fortunately CoreOS have done most of the hard work for us. CoreOS have a starter repo that sets up a single or multi-node CoreOS cluster with Kubernetes installed and ready to go. The repository has scripts to build a Kubernetes bound CoreOS cluster on top of Vagrant, AWS or more generically across self-controlled VMs or bare metal. These scripts configure all the services, TLS certificates and more. If you’ve read the Kubernetes set up documentation you’ll know this kick-starter coreos-kubernetes repo is a massive time saver.
In the remainder of this post I’ll show you how you can get your own multi-node Kubernetes + CoreOS environment running distributed wordpress.
Install VirtualBox and Vagrant
See this link for details.
You’ll need a database
I’m still not sold on persistence / databases in containers. So for the purpose of this demo we’ll set up a standard Ubuntu VM with Vagrant and Virtualbox.
Clone my mysql-vagrant repo locally:
1 | git clone git@github.com:shaundomingo/mysql-vagrant.git |
In a few minutes you’ll have a VM running with MySQL installed. Have a look here for the database access credentials: https://github.com/shaundomingo/mysql-vagrant.
If you want to SSH onto your database server:
1 | vagrant ssh |
Clone the CoreOS-Kubernetes GitHub repo
1 | git clone https://github.com/coreos/coreos-kubernetes.git |
Deploy some VirtualBox VMs for the Kubernetes stack using Vagrant
Determine your topology
The repo comes with everything you need to either set up a single-node or multi-node topology. For this example, we’ll take the multi-node approach. In the multi-node topology, your VMs are split into 3 components:
- Kubernetes Controller
- Kubernetes Workers
- CoreOS etcd
Having these components separated out is a good idea … any one of the components can be updated or taken out in isolation. You wouldn’t want your workers going down if the Kubernetes Controller went under the knife. Although you’d probably want at least 2 instances of each component (particularly etcd!).
1 | cd coreos-kubernetes/multi-node/vagrant |
Notice in the vagrant directory a config.rb.sample file. For fun, let’s cp this file and edit the file leaving a single controller, 3 workers and one etcd.
1 | cp config.rb.sample config.rb |
Change config.rb so that you’re left with the following, save and exit. Oh, and make sure you have about 2.5Gb of RAM free or your system could start weeping uncontrollably.
1 |
Now we make a couple of minor changes to the Vagrantfile so we can access the Kubernetes deployed app from all worker nodes at the end:
1 | diff --git a/multi-node/vagrant/Vagrantfile b/multi-node/vagrant/Vagrantfile |
Deploy your stack
I hate to say it, but it’s as easy as:
1 | vagrant up |
Why is it easy? Well the CoreOS team have done the hard work for you. Take a look at the Vagrantfile. The Vagrantfile does the following:
- Dynamically determines IPs for the CoreOS cluster
- Sets up your TLS config (see ../ssl/init-ssl-ca) for magic
- Provisions each etcd (needs to be up first), controller, then worker VMs bundling the ssl files as a tar in each VM, ready for consumption
Assuming you’ve run vagrant up, watch it do all the things. When it’s finished you should be able to view the state of the cluster and ssh into every VM:
1 | vagrant status |
Kubernetes is using etcd to store configuration and data relating to the Kubernetes registry and scheduler. You can be fairly certain that if that guy goes down, it’s going to cause some issues.
SSH into all of your nodes and check on their state. If you’re on a Macbook Air, you could feel some heat and hear some serious RPMs from your CPU fan. That’s ok, all in good fun.
Log onto the etcd VM (e1) and take a look at the values in etcd.
1 | vagrant ssh e1 |
Later you’ll be able to check etcd to see how kubernetes stores info about replication controllers, services, endpoints, namespaces and events:
1 | vagrant ssh e1 |
Configure your shell to talk to your new kube cluster
You’ll need to download the kubernetes kubectl utility (go binary) for your operating system.
Take a look at the kubectl releases page to gather the latest version number then plug it into the following curl commands (s/VERSION/actual version/).
First, download the latest kubernetes binary for *nix (go Go!):
1 | curl -O https://storage.googleapis.com/kubernetes-release/release/vVERSION/bin/linux/amd64/kubectl |
Or an OS X workstation:
1 | curl -O https://storage.googleapis.com/kubernetes-release/release/vVERSION/bin/darwin/amd64/kubectl |
Put the kubectl binary somewhere on your path and/or change your path in your .zshrc or .bashrc so that it’s accessible each time your terminal loads. The easiest place to put this is /usr/local/bin.
Now we need to set up the configuration so your client can talk to your new multi-node cluster:
1 | cd coreos-kubernetes/multi-node/vagrant |
Test to see your Kubernetes cluster is running
1 | $ kubectl get nodes |
If you see what I see, you’re heading in the right direction. Hoorah!
Let’s deploy wordpress
In a previous post I tried to get 10s of wordpress instances firing up through CoreOS’ native scheduler fleet. The challenge is that CoreOS does not provide native load balancing across workloads. This is where Kubernetes comes in. Kubernetes has “replication controllers” and “services”. Replication controllers set up a strategy for deploying your services into “pods” as containers across your cluster. Services abstract access to Kubernetes pods via endpoints. A pod is a colocated group of applications running with a shared context. You never deal directly with pods, instead, replication controllers which manage the lifecycle of pods.
In my previous CoreOS exercise I used vulcand + etcd as the mechanism for service discovery and load balancing. I did this by using fleet unit files which would poll and listen for new containers as they were fired up and add the relevant service endpoint into vulcand when ready. While the process worked, there were many problems:
- Vulcand is still new and documentation is understandably minimal
- So much escaping in unit files, it called out for a DSL
- Sticky-sessions was a to-do feature
- Deploying unit files felt repetitive, boring and hacky. It just didn’t feel right.
So with that, it’s time to look to Kubernetes, today’s gold class scheduling standard.
We take the CoreOS + Fleet + Etcd + Vulcand + Docker architecture …
1 | +---------80----------+ |
NB: EtcD on each node in this example.
… and turn it into the Kubernetes architecture (CoreOS + Kubernetes + Etcd + Docker):
NB: See this link for a full breakdown on the Kubernetes architecture:
1 | +---------80----------+ |
NB: c(l,m,n,o,p) are containers. For our exercise we’ll deploy one Wordpress container per pod, but you don’t have to. I like to think of pods as a great way to isolate your application components. Tightly coupled would work as peas in a pod, ha!
You may recall that we deployed two more Virtual Machines, c1 (the controller) and e1 (etcd). Your kubectl binary makes a connection to the master components (authz, REST api) on the controller (c1) virtual machine. The Controller manages workloads on all your worker nodes.
1 | +--------------------+ +--------------------+ |
Note on our local machine Kubernetes does not support load balancers across multiple worker nodes (how could it?). So we use a NodePort service type in our replication controller (RC) which exposes our Kube proxy service (which runs on every worker node) on an externalised port 30100 which we port forward to from our local machine as 30100, 30101, 30102 per worker node w1,2,3 in our Vagrantfile (these were the changes we made earlier to get access).
Since we’ve already set up a mysql database, deploying wordpress is particularly simple. We just pass in the required database connection details as environment variables in the replication controller container spec.
We’ll get 3 pods running, each running a single Wordpress docker container.
Download my sample repo containing this simple Kubernetes example
Clone my repo, take a look at the files in the repo and then run the following:
1 | git clone git@github.com:shaundomingo/kubernetes-examples.git |
Since I’ve previously built a wordpress container, I’m going to leverage that container image sdomsta/wp, available on Dockerhub.
You should now be in the clusterable-wordpress directory, ready to get some wordpress pods running.
Get wordpress scheduled
Before you do this, ensure you have your mysql-vagrant VM running in VirtualBox! The wordpress container will need it to fire up.
From here, create a replication controller that will ensure 3 replicas of your wordpress container spec is up and running. If an error occurs within any pod, the kubernetes scheduler will try to revive them by restarting any failed container. You’ll create the replication controller from a spec (wordpress-controller.json) that gets written into etcd for persistence via the kubernetes controller services.
1 | $ kubectl create -f wordpress-controller.json |
The wordpress app is now live. But you won’t yet be able to hit it. This is where we come to understand the kubernetes proxy.
Create a service
We now need a service that will expose your pods to the outside world. There are a number of ways to do this including type=LoadBalancer and type=NodePort.
Since we don’t have a load balancer on our machine that can talk through to our host-only interface, we’ll create a simple NodePort service that will listen on a port 30100 on every worker node, via the kube proxy.
We’ll then be able to hit the service on each worker node’s VirtualBox host-only interface (http://172.17.4.201:30100, http://172.17.4.202:30100, http://172.17.4.203:30100), or on the port forward port on your local machine (http://127.0.0.1:30100, http://127.0.0.1:30101, http://127.0.0.1:30102 respectively).
1 | $ kubectl create -f wordpress-service.json |
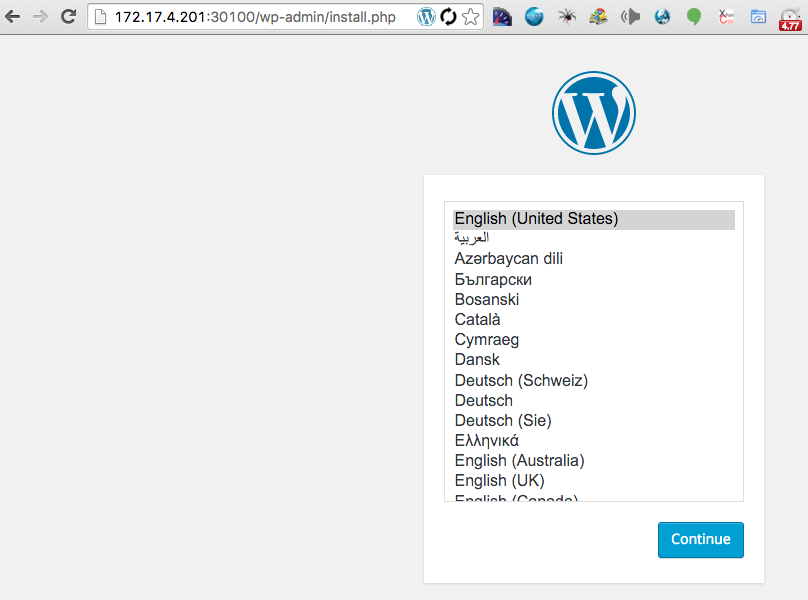
Up, up and away. Try and hit your wordpress instance: http://172.17.4.201:30100/.
If all is well you should now see the wordpress installation screen.
How can I validate it’s all working successfully?
Use kubectl to query the kubernetes API to ensure all the components are up and running and published correctly.
1 | $ kubectl get rc,pods,services -o wide |
You’ll note a single wordpress replication controller, 3 pods (running your wordpress containers) and a wpfrontend service of type NodePort (that is exposing 30100). You know so because you saw so.
1 | CONTROLLER CONTAINER(S) IMAGE(S) SELECTOR REPLICAS AGE |
Each pod fires up a wordpress container using the specified sdomsta/wp docker image. Keep running the following command until all pods are ‘Running’:
1 | kubectl get pods |
You can check that your wpfrontend service is connected to ports exposed by your pods by looking at your endpoints:
1 | $ kubectl get endpoints |
That command is interesting because it demonstrates the magic of Kubernetes. Each pod gets allocated its own private endpoint IP. The kube proxy magically knows how to connect to it and balance traffic across each of the endpoints. Very cool.
For fun you should try and break things. Try and scale up until your machine dies. Turn off your database VM, turn off a CoreOS worker VM. Did Kubernetes reschedule your pods? I had some issues when my machine was heavily resource constrained, do you?
How do I scale?
The moment you’ve surely been waiting for. Well good news, it’s very simple, and super fast.
1 | $ kubectl scale rc wordpress --replicas=30 |
Watch the pods as they move from Pending to Running (if you’re quick enough!). When you’re done playing, scale back down, noticing how Kubernetes selects the pods to scale back down.
1 | $ kubectl scale rc wordpress --replicas=3 |
Do you get the same three containers after scaling back down? Maybe, but unlikely.
Some other things I’ve learned
Debugging containers in pods that won’t start
If your pod won’t Run successfully, it may be very difficult to diagnose the actual problem. I found that entrypoint.sh logs didn’t filter their way through to the kubectl logs. To get around this I ssh’d onto the coreos worker in question (vagrant ssh w(n)) and took a look at /var/log/containers. That directory contains a log per launched container, which is mighty helpful to examine faults.
Interestingly journalctl didn’t list the errors either.
Easy access to the kubernetes API
There is an authorization layer in front of all Kubernetes services. Getting access to the kubernetes controller API is best done via kubectl proxy which will proxy the remote API through a port (default 8001) on your local machine.
This is advantageous because other Kubernetes services like the kube-ui and kubedash are published from the controller node, and most of those utilities access the kubernetes API on it’s internally published port 443 which is not available to you outside of the guest on 443 (unless you port forward 443 which would be strange)…
If you need to regenerate your CoreOS/Kubernetes cluster
1 | cd coreos-kubernetes/multi-node/vagrant |
I’ve done this about 50 times I’d say.
My host system is crashing when deploying replication controllers / services
I think it might be VirtualBox. Make sure you’re on the latest version of VirtualBox and try again.
More iceberg to come
That’s just the tip of the iceberg. There is so much more to show and tell regarding Kubernetes. I’m most interested in utilities like the kube-ui / kubedash and usage monitoring and how kubernetes deals with high workloads, resource management and exception scenarios. In my next post I’ll talk about how you monitor the health of your replicated pods.